Your cart is currently empty!

Run:AI takes your AI and runs it, on the super-fast software stack of the future
Startup Run:AI exits stealth, promises a software layer to abstract over many AI chips
It’s no secret that machine learning in its various forms, most prominently deep learning, is taking the world by storm. Some side effects of this include the proliferation of software libraries for training machine learning algorithms, as well as specialized AI chips to run those demanding workloads.
The time and cost of training new models are the biggest barriers to creating new AI solutions and bringing them quickly to market. Experimentation is needed to produce good models, and slightly-modified training workloads could be run hundreds of times before they’re accurate enough to use. This results in very long times-to-delivery, as workflow complexities and costs grow.
Today Tel Aviv startup Run:AI exits stealth mode, with the announcement of $13 million in funding for what sounds like an unorthodox solution: rather than offering another AI chip, Run:AI offers a software layer to speed up machine learning workload execution, on premise and in the cloud.
The company works closely with AWS, and is a VMware technology partner. Its core value proposition is to act as a management platform to bridge the gap between the different AI workloads and the various hardware chips, and run a really efficient and fast AI computing platform.
AI chip virtualization
When we first heard about it, we were skeptical. A software layer that sits on top of hardware sounds a lot like virtualization. Is virtualization really a good idea when it’s all about being as close to the metal as possible to squeeze as much performance out of AI chips as possible? This is what Omri Geller, Run:AI co-founder and CEO thinks:
“Traditional computing uses virtualization to help many users or processes share one physical resource efficiently; virtualization tries to be generous. But a deep learning workload is essentially selfish since it requires the opposite:
It needs the full computing power of multiple physical resources for a single workload, without holding anything back. Traditional computing software just can’t satisfy the resource requirements for deep learning workloads.”
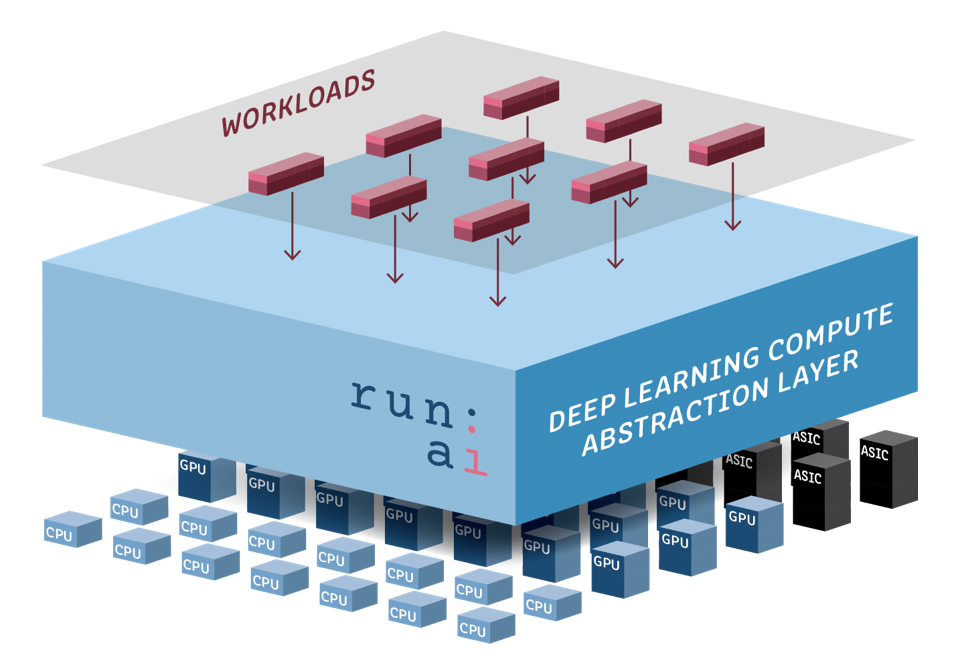
Run:AI works as an abstraction layer on top of hardware running AI workloads
So, even though this sounds like virtualization, it’s a different kind of virtualization. Run:AI claims to have completely rebuilt the software stack for deep learning to get past the limits of traditional computing, making training massively faster, cheaper and more efficient.
Still, AI chip manufacturers have their own software stacks, too. Presumably, they know their own hardware better. Why would someone choose to use a 3rd party software layer like Run:AI? And what AI chips does Run:AI support?
Geller noted that there is diversity in hardware for AI that is currently available and will become available in the next few years. Currently in production the Run:AI platform supports Nvidia GPUs, while Geller said that Google’s TPUs will be supported in next releases. He went on to add that other deep learning dedicated chips will be supported as well once they are ready and available for general use. But that’s not all.
Machine learning workload diversity and the need for a management platform
Geller pointed out that in the new era of AI, diversity comes not only in the various available hardware chips but also in the workloads themselves. AI workloads include Support-Vectors, decision tree algorithms, fully connected neural networks, Convolutional Neural Networks (CNNs), long-short-term memory (LSTM) and others:
“Each algorithm fits a different application (decision trees for recommendation engines, CNNs for image recognition, LSTMs for NLP, and so on). These workloads need to run with different optimizations – different in terms of distribution strategy, on different hardware chips, etc.
A management platform is required to bridge the gap between the different AI workloads and the various hardware chips and run a real efficient and fast AI computing platform. Run:AI’s system runs all an organization’s AI workloads concurrently, and therefore can apply macro-optimizations like allocating resources among the various workloads”.
http://knowledgeconnexions.wordlift.io/?post_type=post&p=14
Run:AI uses graph analysis coupled with a unique hardware modeling approach to handle deep learning optimizations and manage a large set of workloads
Geller explained that Run:AI uses graph analysis coupled with a unique hardware modeling approach to handle such optimizations and manage a large set of workloads. This, he said, allows the platform to understand the computational complexity of the workloads, matching the best hardware configuration to each task while taking into account business goals and pre-defined cost and speed policies.
Geller added that Run:AI also automatically distributes computations over multiple compute resources using hybrid data/model parallelism, treating many separate compute resources as though they are a single computer with numerous compute nodes that work in parallel. This approach optimizes compute efficiency and allows you to increase the size of the trainable neural network.
Running machine learning model training workloads, however, is heavily reliant on feeding them with the data they need. In addition, people usually develop their models using TensorFlow, Keras, PyTorch, or one of the many machine learning frameworks around.
So how does this all come together – what do machine learning engineers have to do to run their model on Run:AI, and feed it the data it needs? Importantly, does it also work in the cloud – public and private? Many AI workloads run in the cloud, following data gravity.
Integrating with machine learning frameworks and data storage, on premise and in the cloud
Geller said that one of the core concepts of Run:AI is that the user doesn’t have to change workflows in order to use the system:
“Run:AI supports both private clouds and public clouds such that our solution works in hybrid/multi cloud environments. The company works closely with VMware (technology partner) and with AWS in order to maximize resource utilization and minimize costs.
Run:AI can operate with Docker containers pre-built by the user, containers pre-built by the Run:AI team, or on bare metal. Most of Run:AI optimizations can be applied to any containerized workload running with any framework. The low-level system that parallelizes a single workload to run on multiple resources can be applied to graph-based frameworks, currently supporting TensorFlow and Keras in production and soon PyTorch as well.
Data is streamed to the compute instance either via containerized entry point scripts, or as part of the training code running on bare metal hardware. Data can be stored in any location including cloud storage in public clouds and network file systems in private clouds”.
Again, this made us wonder. As Run:AI claims to work close to the metal, it seemed to us like a different model, conceptually, from the cloud where the idea is to abstract from the hardware, and use a set of distributed nodes for compute and storage. Plus, one of the issues with Docker / Kubernetes at this time is that (permanent & resilient) data storage is complicated.
In most cases, Geller said, data is stored in a cloud storage like AWS S3 and pipelined to the compute instance:
“The data pipeline typically includes a phase of streaming the data from the cloud storage to the compute instance and a preprocessing phase of preparing the data to be fed to the neural net trainer. Performance degradation can occur in any of these phases.
The Run:AI system accounts for data gravity and optimizes the data streaming performance by making sure the compute instance is as near as possible to the data storage. The low-level features of the Run:AI system further analyze the performance of the data pipeline, alerting users on bottlenecks either in the data streaming phase or in the preprocessing step while providing recommendations for improvement”.
Geller added that there is also an option for an advanced users to tweak the results of the Run:AI layer, manually determining the amount of resources and the distribution technique, and the workload would be executed accordingly.
Does Run:AI have legs?
Run:AI’s core value proposition seems to be acting as the management layer above AI chips. Run:AI makes sense as a way of managing workloads efficiently across diverse infrastructure. In a way, Run:AI can help cloud providers and data center operators hedge their bets: rather than putting all their eggs in one AI chip vendor basket, they can have a collection of different chips, and use Run:AI as the management layer to direct workloads where they are most suitable for.
Promising as this may sound, however, it may not be everyone’s cup of tea. If your infrastructure is homogeneous, consisting of a single AI chip, it’s questionable whether Run:AI could deliver superior performance than the chip’s own native stack. We asked whether there are any benchmarks: could Run:AI’s performance be faster than Nvidia, GraphCore, or Habana, for example? It seems at this point there are no benchmarks that can be shared.
Run:AI founders, Omri Geller and Dr. Ronen Dar. Raun:AI is in private beta with paying customers and working with AWS and VMware. General availability is expected in Q4 2019
Geller, who co-founded Run:AI with Dr. Ronen Dar and Prof. Meir Feder in 2018, said that there are currently several paying customers from the retail, medical, and finance verticals. These customers use Run:AI to speed up their training and simplify their infrastructure.
He went on to add that customers also use the system as an enabler to train big models that they couldn’t train before because the model doesn’t fit into a single GPU memory: “Our parallelization techniques can bypass these limits. Customers are able to improve their model accuracy when accelerating their training processes and training bigger models”.
Run:AI’s business model is based on subscription and the parameters are a combination of the number of users and the number of experiments. The cost depends on the size and volume of the company, Geller said. Currently Run:AI is in private beta, with general availability expected in 6 months.
Content retrieved from: https://www.zdnet.com/article/take-your-ai-and-run-it-on-the-super-fast-software-stack-of-the-future/.
by
Tags:
Leave a Reply